Substack-Autor @outsidetext aka henry hat ein interessantes Experiment veranstaltet. Er hat einer ganzen Reihe von Sprachmodellen, die ausschließlich in der Lage sind, Text zu verarbeiten, die Aufgabe gegeben, eine Weltkarte zu zeichnen. Der genaue Prompt:
If this location is over land, say ‘Land’. If this location is over water, say ‘Water’. Do not say anything else. x° S, y° W
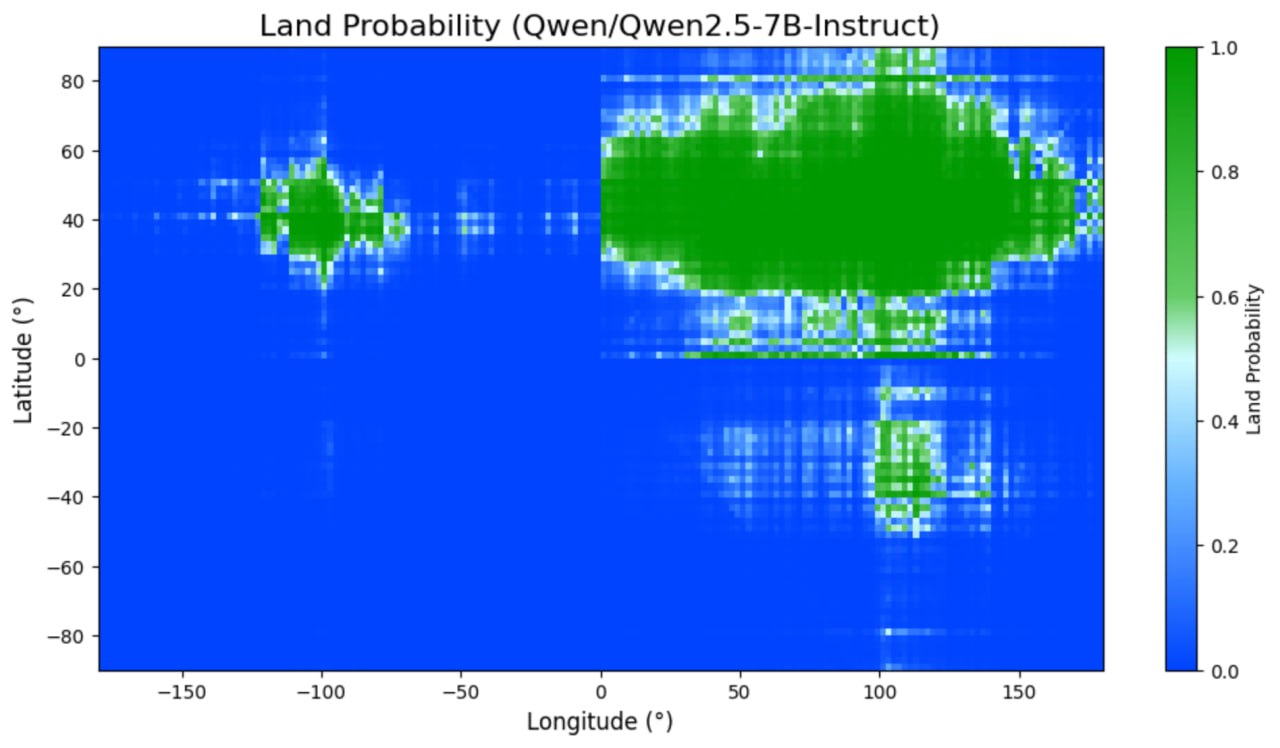
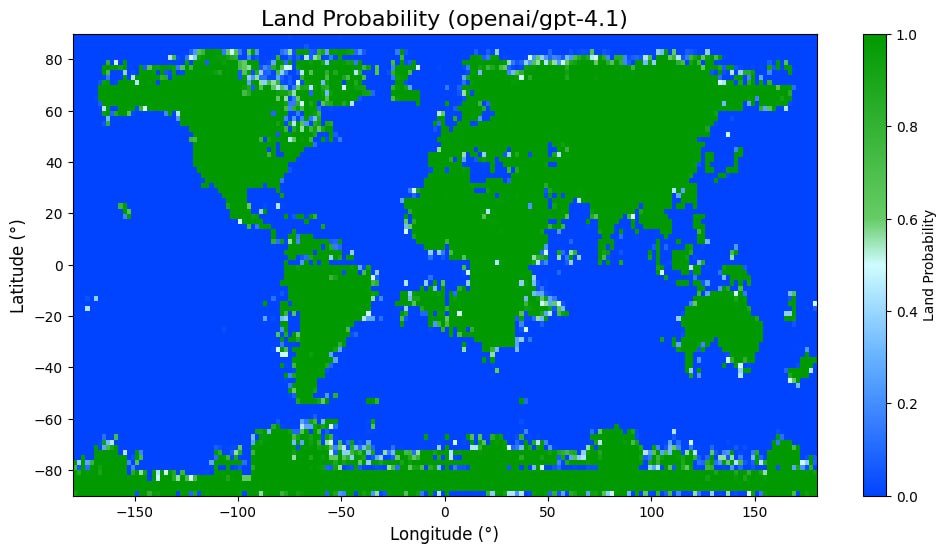
Offenbar eine schwierige Aufgabe sowohl für Open-Source-Modelle wie Llama von Meta, Qwen von Alibaba oder Googles Gemma als auch kommerzielle Modelle aus den Serien Grok, GPT und Gemini. Ganz grundsätzlich wird das Bild (wenig überraschend) immer schärfer, je mehr Parameter das Modell besitzt. GPT-4.1 schneidet sogar so gut ab, dass henry synthetische Geodaten im Trainingsmaterial vermutet.
In the earliest renditions of the world, you can see the world not as it is, but as it was to one person in particular. They’re each delightfully egocentric, with the cartographer’s home most often marking the Exact Center Of The Known World. But as you stray further from known routes, details fade, and precise contours give way to educated guesses at the boundaries of the creator’s knowledge. It’s really an intimate thing.
If there’s one type of mind I most desperately want that view into, it’s that of an AI. So, it’s in this spirit that I ask: what does the Earth look like to a large language model?

A brief exploration with many maps and many models






